LLM API Costs Explained (2025): Pricing Models, Comparisons, & Savings
Pricing Models, Comparisons, & Savings — a qualitative guide to how LLM billing works, the pricing models behind it, hidden fees, and budget tactics you can apply today.
LLM API COSTS
9/14/20254 min read
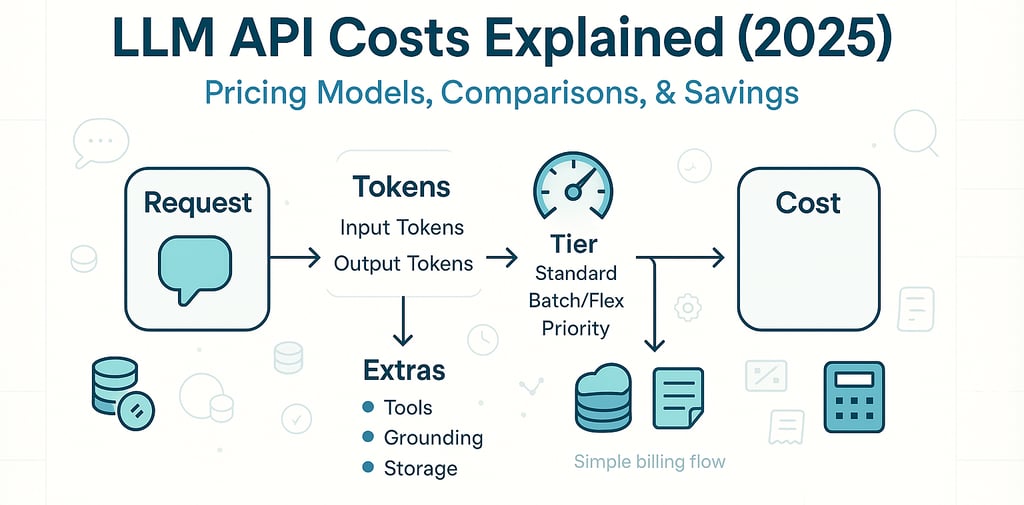
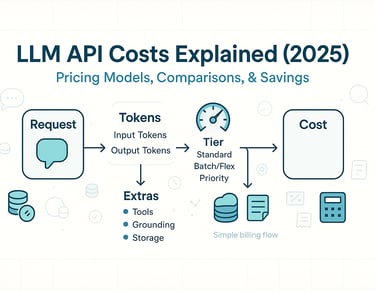
The Three Pricing Lenses (tokens, requests/sessions, tiers)
Why output tokens matter more than you think
Across providers, output tokens often carry a higher rate than input. That means long, chatty answers quietly inflate spend. The fastest win is to cap outputs and prefer structured formats (bullets, JSON, terse summaries). This input/output split appears across OpenAI, Anthropic, and Google tables.
When per-request or session pricing shows up
Some features bill per session or per request (for example, tool sessions or realtime modes), on top of token usage. OpenAI’s platform is explicit about separate line items for built-in tools.
Tiers (Standard, Batch/Flex, Priority) and what they trade
Standard: balanced latency and price—your default.
Batch/Flex: cheaper, but slower/asynchronous. Ideal for backfills, ETL, analytics, and non-interactive tasks. (OpenAI exposes Batch; many ecosystems offer “lower-latency-priority” queues.) OpenAI
Priority: pay more for lower latency and tighter SLAs—best for live UIs. (OpenAI references a priority tier.)
Who’s Who: Provider Landscape (qualitative)
OpenAI: tools, tiers, and platform “extras”
OpenAI is “batteries included.” You get models plus built-in tools (web search, file search, code interpreter), clear Batch docs, and multiple service tiers. The tradeoff: those tools are separate line items you must meter.
Anthropic: long context & caching mindset
Anthropic leans into very long contexts (with distinct pricing when you cross large thresholds) and prompt caching, which can cut effective cost for prompts that repeat large blocks of text (like system instructions or persistent knowledge).
Google (Gemini/Vertex): grounding & caching-centered design
Google treats grounding with Google Search and context caching as first-class concepts. You get daily grounded allowances before overages, and caching can reduce input cost when reusing context. Plan for retrieval strategy and cache policy from day one.
Cost Drivers You Control (and how)
Context windows & retrieval habits
Big contexts are convenient, but input tokens balloon fast. Prefer retrieve-then-shrink: embed your corpus, pull only the few most relevant chunks, and summarize before passing to the model. Cache stable instructions so you don’t resend them each turn. (Anthropic prompt caching; Google context caching.)
Model class vs. task complexity
Don’t default to the frontier model. Use mini/flash/haiku-class models for routine tasks and route up only when complexity demands it. Most teams save more from right-sizing the model than from micro-tuning prompts.
Volume, verbosity, and latency expectations
High traffic + long answers + low latency demands = expensive. Tame verbosity with templates and output caps, and move non-interactive workloads to Batch/Flex queues.
Hidden Fees in the Real World
Tool calls (search, file search, code interpreter)
On OpenAI, web search tool calls, file search storage, and code interpreter sessions are billed in addition to tokens. If agents can call tools freely, set budgets and alerts.
Grounding, storage, and indexing considerations
With Google, grounded prompts come with daily free allowances and then overage pricing. Treat grounding as a separate budget. Caching also has storage characteristics—plan retention and eviction.
Batch vs. real-time tradeoffs (and “Flex”-style queues)
Batch is your friend for long-running or bulk work. You trade latency for lower effective rates—perfect for ETL, evaluation, bulk summarization, report generation, and offline inference. (OpenAI’s Batch and tier docs explain the pattern.)
Budgeting & Forecasting: A Practical Playbook
Set token budgets and output caps
Define max output tokens per request and per user action. Use concise, structured responses (bullets, JSON) to avoid output drift.
Cache, then compress
Cache stable system prompts, policies, and recurring knowledge—you’ll stop paying to resend them. Compress long docs: summarize, chunk, and only pass relevant snippets. (Anthropic prompt caching; Google context caching.)
Route smartly
Build a router: start on a small/fast model and escalate only if quality checks fail (guardrails, unit tests, or simple evals). This alone can slash spend.
Batch what isn’t urgent
Schedule backfills, audits, and bulk generation into Batch/Flex lanes. Users won’t notice and you’ll reduce your per-token effective rate.
Meter tool calls and storage
Treat web/file search and interpreter sessions as first-class metrics. Put soft limits per request and raise alerts on spikes. (OpenAI lists these line items clearly.)
Measure cost-per-outcome, not cost-per-call
Track cost per resolved ticket, per generated page, or per successful action. This reframes debates from “cheapest tokens” to “best ROI.”
FAQs
1) Why do costs spike even with short prompts?
Because outputs are often priced higher. Set output caps and keep responses structured.
2) Is long context always worth it?
No. It’s powerful for deep reasoning, but you should retrieve only what’s relevant and cache repeated context to avoid input bloat.
3) Does grounding change my costs?
Yes—Google provides daily grounded allowances and bills overages; treat grounding as a distinct budget line.
4) Are tools like web search and file search “free”?
They’re billed separately (plus tokens). Budget and alert on them from day one.
5) Can I put everything on Batch/Flex?
Use Batch/Flex for non-interactive jobs. Keep user-facing features on Standard/Priority for responsiveness.
6) What’s the single biggest habit that saves money?
Short, structured outputs plus routing to smaller models first—those two changes often deliver the biggest gains.
Conclusion
You don’t need a wall of figures to manage LLM API Costs. Focus on the four levers—input, output, tier, and extras—and you’ll keep spend predictable. Cache what repeats, retrieve only what matters, batch the rest, and reserve premium models/tier for the moments that truly need them. For specifics, always cross-check the official provider pages before launch or scale: OpenAI’s tool and tier line items, Anthropic’s long-context and caching, and Google’s grounding allowances and caching docs are the source of truth.
Follow us on other platforms.
Specializing in software consultancy, AI consultancy, and business strategy
We are just a mail away!
© 2024. All rights reserved.